Prerequisite - Train-test-split¶
Split your dataset in two parts.
Usually, the larger split is used to train the model, and the smaller one for testing it.

Goal: Create a model that assigns a single class to each object.
$ F_{\theta}: \vec{x} \rightarrow \mathbb{N} $
Requirements:
Goal: Create a model that predicts a continuous value for each object.
$ F_{\theta}: \vec{x} \rightarrow \mathbb{R}$
Requirements:
Both classification and regression require annotated examples to train $F$. They fall into the category of supervised techniques.
In most cases training data for any supervised technique has to be manually annotated by humans.
While, at first glance, this process seems to be straightforward, it can become arbitrarily complex, depending on the problem to solve!
To facilitate the annotation process there are some best practices:
In methodologically oriented fields like classical NLP, the annotation process often (but not always) plays a minor role because the overall goal is to develop new methods that push the performance across various use-cases or datasets.
In fields like Computational Humanities, which employ data-science methods to answer research questions about certain objects, annotations are much more important because they serve a critical (two-folded) role.
Since CH research questions are often based on assumptions made by qualitative work or vague theories, converting them into an annotation scheme is complex.
While creating annotations, you must reason about your object of interest and the questions you are working on, forcing you to precisely specify your investigation's phenomena.
Example: Labeling depiction of violence in German Dime-novels.
How can violence be defined?
Er zog jetzt irgendetwas unter seiner Kleidung hervor. Brenda konnte es nicht genau sehen. Aber im nächsten Moment blitzte das Mündungsfeuer einer Waffe auf. Die Kugel traf Brenda mitten in die Brust. Sie stützte sich noch auf den Kotflügel ihres Wagens, ehe sie zusammenbrach und regungslos auf dem nassen Boden liegen blieb.
Mit brachialer Gewalt krachte der Meteorit in den Schutzschild ! Das Shuttle wurde durchgerüttelt , die Energiekonverter summten wie ein zorniger Bienenschwarm . Metall kreischte und schien sich zu verbiegen , während eine Serie greller Leuchterscheinungen vor dem Cockpit aufflackerte.
If multiple annotators annotate the same examples, the inter-annotator agreement measures how reliable the annotators reach the same conclusion.
Thus it is also an estimate of the difficulty of the annotations task.
The inter-annotator agreement can also be viewed as an upper bound for the performance of any machine learning algorithm since "super-human" performance is rarely (if ever) realistic.
To measure the agreement, multiple metrics have been proposed.
Measures the agreement of two annotators $A_1$ and $A_2$ on $N$ instances with $C$ classes.
$$\kappa = \frac{A_O - A_E}{1 - A_E}$$Cohens Kappa is measures class-based agreement between two annotators $A_1$ and $A_2$ on $N$ instances each being assigned one of $C$ class labels by both.
$$ \kappa = \frac{A_O - A_E}{1 - A_E} $$import pandas as pd
import numpy as np
contingency_table = pd.DataFrame(
data=[
[10, 10, 0],
[5, 45, 10],
[1, 4, 15]
],
index=[f"A1_C{c}" for c in range(1, 4)],
columns=[f"A2_C{c}" for c in range(1, 4)],
)
contingency_table
| A2_C1 | A2_C2 | A2_C3 | |
|---|---|---|---|
| A1_C1 | 10 | 10 | 0 |
| A1_C2 | 5 | 45 | 10 |
| A1_C3 | 1 | 4 | 15 |
def expected_agreement(contingency_table: pd.DataFrame, verbose: bool = True) -> float:
a1_c_counts = contingency_table.sum(axis=1)
if verbose: print(f"A1 class frequencies:\n{a1_c_counts}")
a2_c_counts = contingency_table.sum(axis=0)
if verbose: print(f"A2 class frequencies:\n{a2_c_counts}")
n_instances = contingency_table.values.sum()
a_e = (1 / n_instances**2) * (a1_c_counts.values * a2_c_counts.values).sum()
if verbose: print(f"Expected agreement is {a_e}")
return a_e
def observed_agreement(contingency_table, verbose: bool = True):
a_o = np.diag(contingency_table).sum() / contingency_table.values.sum()
if verbose: print(f"Observed agreement is {a_o}")
return a_o
def cohens_kappa(contingency_table: pd.DataFrame, verbose: bool = True) -> float:
a_o = observed_agreement(contingency_table=contingency_table, verbose=verbose)
a_e = expected_agreement(contingency_table=contingency_table, verbose=verbose)
agreement = (a_o - a_e) / (1 - a_e)
return agreement
cohens_kappa(contingency_table)
Observed agreement is 0.7 A1 class frequencies: A1_C1 20 A1_C2 60 A1_C3 20 dtype: int64 A2 class frequencies: A2_C1 16 A2_C2 59 A2_C3 25 dtype: int64 Expected agreement is 0.436
0.4680851063829786
If multiple annotators annotate data without reaching a perfect agreement, how do we handle the disagreement cases to create a definitive gold-standard version of our dataset?
Options:
Suppose we have created or obtained a gold-standard dataset and trained a model on it.
How do we asses the model's performance?
Evaluation metrics for
To assess the model's performance, we must test it on data it hasn't seen during training!
To create this, we can either:
Split your dataset in two parts.
Usually, the larger split is used to train the model, and the smaller one for testing it.
The single train-test-split strategy has an obvious downside, by chance, you can end up with a random split that is not representative of the whole dataset (too simple, too hard, not containing all labels in case of label imbalance, or extreme multiclass settings)
$K$-Fold Cross-Validation offers to reliable estimate the true model's performance, albeit at higher computational costs.
The process is simple: The dataset is split into $K$ equally sized splits and $K$ different models are trained by successively selecting one split as test-set and training on all other splits.
To obtain final results, you can average the scores over all splits.

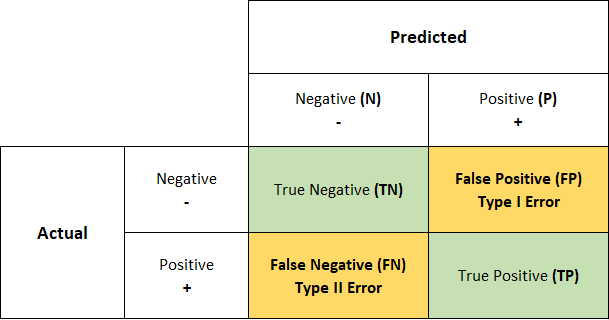
Accuracy is the simplest way to measure the quality of a classification model.
It computes the amount of correct decisions:
$$ Accuracy = \frac{TP + TN}{TP + TN + FP + FN} $$Accuracy is a global measure that doesn't consider class distributions.
It can be heavily affected in imbalanced cases.
Label imbalance - Example
Suppose we have a dataset containing some health features for a large group of patients; we want to classify whether a patient has cancer.
Luckily, most people do not have cancer, so our chance to encounter patients with cancer is small.
The resulting dataset might look similar to this:
import numpy as np
import pandas as pd
import seaborn as sns
import matplotlib.pyplot as plt
from sklearn.model_selection import train_test_split
np.random.seed(42)
# Generate some mock data (we actually don't need those features)
X = np.random.randn(10_000, 100)
# 0 => No Cancer, 1 => Cancer
y = np.random.choice(2, p=(0.99, 0.01), size=(10_000))
print(np.unique(y, return_counts=True))
# Generate train-test-split
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42)
(array([0, 1]), array([9894, 106]))
# Build a "classifier" and use it to predict our data.
from sklearn.base import BaseEstimator
class LazyClassifier(BaseEstimator):
def fit(self, X, y):
unique_labels, counts = np.unique(y, return_counts=True)
self.most_common_label_ = unique_labels[np.argmax(counts)]
return self
def predict(self, X, y=None):
return np.full(X.shape[0], fill_value=self.most_common_label_)
clf = LazyClassifier().fit(X_train, y_test)
y_pred = clf.predict(X_test)
# Compute the accuracy
def accuracy(y_true: np.ndarray, y_pred: np.ndarray) -> float:
return (y_true == y_pred).astype("int").mean().item()
print(f"The classifier obtained an accuracy of {accuracy(y_test, y_pred)}")
The classifier obtained an accuracy of 0.9873333333333333
Accuracy can be useful for rating a model's performance, but only if classes are roughly uniformly distributed.
Another downside of this metric is its inability to differentiate the performance between classes.
To more accurately describe a model's performance, we can express its performance in two terms:

To jointly express both precision and recall, we can aggregate them into a single score using the harmonic mean:
$$ F1 = 2\frac{Precision \cdot Recall}{Precision + Recall} $$The F1-score is a special version of the more general $F\beta$-score: $$ F\beta = (1 + \beta^2) \cdot \frac{Precision \cdot Recall}{(\beta^2 \cdot Precision) + Recall} $$
By varying $\beta \in +\mathbb{R}$, you can control the relative importance of Recall. (Recall is $\beta$ times as important as Precision)
So far, we only considered binary settings, which makes it easier because errors in class directly affect the only other class.
In multiclass settings, things can become a little bit more tricky because we have to compute precision and recall for each class individually.
Thankfully, we can use scikit-learn to handle the groundwork for us.
from sklearn.metrics import classification_report
from sklearn.datasets import fetch_20newsgroups_vectorized
from sklearn.linear_model import LogisticRegression
train_data = fetch_20newsgroups_vectorized(subset="train")
test_data = fetch_20newsgroups_vectorized(subset="test")
train_target_names = np.array(train_data.target_names)
X_train, y_train = train_data.data, train_target_names[train_data.target]
test_target_names = np.array(test_data.target_names)
X_test, y_test = test_data.data, test_target_names[test_data.target]
clf = LogisticRegression(max_iter=200, n_jobs=-1)
clf.fit(X_train, y_train)
y_pred = clf.predict(X_test)
print(classification_report(y_true=y_test, y_pred=y_pred))
precision recall f1-score support
alt.atheism 0.63 0.61 0.62 319
comp.graphics 0.62 0.69 0.66 389
comp.os.ms-windows.misc 0.72 0.65 0.68 394
comp.sys.ibm.pc.hardware 0.68 0.63 0.66 392
comp.sys.mac.hardware 0.72 0.71 0.71 385
comp.windows.x 0.72 0.68 0.70 395
misc.forsale 0.74 0.85 0.79 390
rec.autos 0.80 0.79 0.79 396
rec.motorcycles 0.80 0.87 0.83 398
rec.sport.baseball 0.70 0.82 0.75 397
rec.sport.hockey 0.88 0.87 0.87 399
sci.crypt 0.87 0.79 0.83 396
sci.electronics 0.63 0.63 0.63 393
sci.med 0.67 0.63 0.65 396
sci.space 0.86 0.84 0.85 394
soc.religion.christian 0.69 0.89 0.78 398
talk.politics.guns 0.62 0.79 0.69 364
talk.politics.mideast 0.83 0.77 0.80 376
talk.politics.misc 0.66 0.47 0.55 310
talk.religion.misc 0.68 0.31 0.43 251
accuracy 0.73 7532
macro avg 0.73 0.72 0.71 7532
weighted avg 0.73 0.73 0.72 7532
from sklearn.metrics import confusion_matrix
conf_mat = pd.DataFrame(data=confusion_matrix(y_true=y_test, y_pred=y_pred), index=test_target_names, columns=test_target_names)
fig, ax = plt.subplots(figsize=(10, 10))
sns.heatmap(conf_mat, annot=True, annot_kws={'size': 5}, ax=ax)
<Axes: >

To measure the quality of a regression model, we can't compute the number of discrete overlaps.
Instead, we need to base our judgement on the amount of error a model makes.
$$ MSE = \frac{1}{N} \sum_{i=1}^{N} (Y_i - \hat{Y}_i)^2 $$All three metrics measure the differences between the actual and predicted values.
Why do we need them? What are the differences?
$\rightarrow$ They all provide a different perspective in the distribution of the offsets!

Suppose you have developed two new classifiers to improve text classification.
You chose the best existing classifier as a baseline to test the performance of your two new models.
To them, you train all classifiers on your benchmark dataset using 5fold-cross-validation and average the f1-macro score over all results.
For simplicity, we generate the data:
def generate_data(n_samples=100):
sample_baseline = np.random.normal(loc=0.70, scale=0.01, size=n_samples)
sample_new_a = np.random.normal(loc=0.702, scale=0.01, size=n_samples)
sample_new_b = np.random.normal(loc=0.71, scale=0.01, size=n_samples)
df = pd.DataFrame({
"seed": list(range(n_samples)),
"score_baseline": sample_baseline,
"score_new_model_a": sample_new_a,
"score_new_model_b": sample_new_b,
})
return df
df = generate_data(100)
df.head()
| seed | score_baseline | score_new_model_a | score_new_model_b | |
|---|---|---|---|---|
| 0 | 0 | 0.697800 | 0.698950 | 0.711911 |
| 1 | 1 | 0.697652 | 0.700998 | 0.714526 |
| 2 | 2 | 0.707310 | 0.718712 | 0.705624 |
| 3 | 3 | 0.689949 | 0.692404 | 0.714525 |
| 4 | 4 | 0.710362 | 0.718426 | 0.728497 |
# Lets plot the score distribution,
sns.histplot(x="score", hue="model", data=df.melt(id_vars="seed", var_name="model", value_name="score"))
<Axes: xlabel='score', ylabel='Count'>

Visually, we can infer that new_model_b outperforms the baseline, while new_model_a seems only slightly better.
But how can we test this assumption, and express its validity numerically?
Significance testing is a statistical method used to determine if the results of a study or experiment are statistically significant, meaning that they are unlikely to have occurred by chance alone.
The goal is to assess whether the observed differences or relationships between variables are real and not simply due to random variation.
The process involves comparing the observed data to an expected distribution under a null hypothesis ($H_0$), which assumes no true effect or relationship exists in the population being studied.
If the observed data significantly deviates from what we would expect under the null hypothesis, it suggests that the observed effect or relationship is statistically significant.
Significance is typically measured using a p-value, representing the probability of observing the data or more extreme results under the null hypothesis.
If the p-value is below the chosen threshold, the null hypothesis is rejected, and it is concluded that there is evidence of a statistically significant effect or relationship.
Typically the p-value threshold is set to $0.05$
Depending on the type or distribution of the data to test, you have to chose a suitable test.
There are two broad types of tests:
Non-parametric test Non-parametric tests do not assume that your data is distributed in a specific way, and can thus be employed more flexibly.
Parametric tests
These tests assume that your data follows a certain distribution (often the normal distribution), and use the distributions' properties ($\rightarrow$ parameters (like mean, variance, etc.)) to compute significance.
These assumptions make them more expressive and reliable compared to non-parametric tests.
The Student's T-Test is used to check if populations have deviating means.
The T-test assumes that the two samples from both populations are normally distributed and have similar variance.
The T-Test comes in three different versions:
We chose two strategies while employing the test:
Formula: $$ t = \frac{\mu_A - \mu_B}{\sqrt{\frac{S^2}{n_A} + \frac{S^2}{n_B}}} $$
The resulting value $t$ is called test-statistic-value and can be used to compute the significance pvalue $\alpha$ used to accept or reject the null-hypothesis. It represents how many standard errors lie between the mean of group A and group B.
In practice, we just use a predefined function to compute the test:
from scipy.stats import ttest_ind
print(f"Baseline->NewModelA (Two-sided) {ttest_ind(df['score_baseline'], df['score_new_model_a'])}")
print(f"Baseline->NewModelA (One-sided: Left mean is less) {ttest_ind(df['score_baseline'], df['score_new_model_a'], alternative='less')}")
print()
print(f"Baseline->NewModelB (Two-sided) {ttest_ind(df['score_baseline'], df['score_new_model_a'])}")
print(f"Baseline->NewModelB (One-sided: Left mean is less) {ttest_ind(df['score_baseline'], df['score_new_model_b'], alternative='less')}")
Baseline->NewModelA (Two-sided) Ttest_indResult(statistic=-1.1836442539095615, pvalue=0.23797301780102723) Baseline->NewModelA (One-sided: Left mean is less) Ttest_indResult(statistic=-1.1836442539095615, pvalue=0.11898650890051361) Baseline->NewModelB (Two-sided) Ttest_indResult(statistic=-1.1836442539095615, pvalue=0.23797301780102723) Baseline->NewModelB (One-sided: Left mean is less) Ttest_indResult(statistic=-5.663557586242623, pvalue=2.582150836087671e-08)
Bases on the test-results, the performance of new_model_a would be classified as being on average on par with the baseline.
The second one-sided tests also confirms that new_model_a on average is not better than the baseline.
Based, on both test for new_model_b, it would be viewed as both deviating, and performing better than the baseline.
In this scenario, we manually generated the data, and can safely assume that the means of the distributions generating the results for the baseline and new_model_a are not the same.
Still, the T-test contradicts this.
This points out one of the weaknesses of most significance tests, there results heavily rely on the sample size.
Let's increase the number of "runs" for our experiment:
df_large = generate_data(10_000)
sns.histplot(x="score", hue="model", data=df_large.melt(id_vars="seed", var_name="model", value_name="score"))
<Axes: xlabel='score', ylabel='Count'>

Now, if we re-run the test on this larger dataset, the tests return different results:
print(f"Baseline->NewModelA (Two-sided) {ttest_ind(df_large['score_baseline'], df_large['score_new_model_a'])}")
print(f"Baseline->NewModelA (One-sided: Left mean is less) {ttest_ind(df_large['score_baseline'], df_large['score_new_model_a'], alternative='less')}")
print()
print(f"Baseline->NewModelB (Two-sided) {ttest_ind(df_large['score_baseline'], df_large['score_new_model_b'])}")
print(f"Baseline->NewModelB (One-sided: Left mean is less) {ttest_ind(df_large['score_baseline'], df_large['score_new_model_b'], alternative='less')}")
Baseline->NewModelA (Two-sided) Ttest_indResult(statistic=-14.47541201495311, pvalue=3.004281497267246e-47) Baseline->NewModelA (One-sided: Left mean is less) Ttest_indResult(statistic=-14.47541201495311, pvalue=1.502140748633623e-47) Baseline->NewModelB (Two-sided) Ttest_indResult(statistic=-69.75427850602864, pvalue=0.0) Baseline->NewModelB (One-sided: Left mean is less) Ttest_indResult(statistic=-69.75427850602864, pvalue=0.0)
Both models would be rated as clearly outperforming the baseline, albeit on different levels.
So, to reliably test our data, we need to make sure to have enough samples!
Sometimes, we can't infer how our samples are distributed.
In these cases, we can use non-parametric tests to test if certain properties of the samples significantly differ.
The Wilkcoxon test can be used to check if the central tendencys of two populations are equal or different. It is based on the ranks of absolute differences between two pairs of values from each sample ($|x_1^j - x_2^j|$) Like the Student's T-Test it comes in different version:
Formula
$$ D_i = x_1^j - x_2^j $$$$ R_i = rang(|D_i|) $$$$ W_+ = \sum_{i=1}^{n} sign( x_1^j - x_2^j > 0)R_i $$$$ W_{-} = \sum_{i=1}^{n} sign( x_1^j - x_2^j < 0)R_i $$$$ W = min(W_+, W_{-}) $$$\rightarrow$ $W$ is the test-statistic-value which can again be used to compute the p-value
We use the same data, as example for the Wilcoxon test:
from scipy.stats import wilcoxon
print(f"Baseline->NewModelA (Two-sided) {wilcoxon(df_large['score_baseline'], df_large['score_new_model_a'])}")
print(f"Baseline->NewModelA (One-sided: Left mean is less) {ttest_ind(df_large['score_baseline'], df_large['score_new_model_a'], alternative='less')}")
print()
print(f"Baseline->NewModelB (Two-sided) {wilcoxon(df_large['score_baseline'], df_large['score_new_model_b'])}")
print(f"Baseline->NewModelB (One-sided: Left mean is less) {ttest_ind(df_large['score_baseline'], df_large['score_new_model_b'], alternative='less')}")
Baseline->NewModelA (Two-sided) WilcoxonResult(statistic=20836232.0, pvalue=3.2885594110579395e-47) Baseline->NewModelA (One-sided: Left mean is less) Ttest_indResult(statistic=-14.47541201495311, pvalue=1.502140748633623e-47) Baseline->NewModelB (Two-sided) WilcoxonResult(statistic=8080701.0, pvalue=0.0) Baseline->NewModelB (One-sided: Left mean is less) Ttest_indResult(statistic=-69.75427850602864, pvalue=0.0)
{kind=link}
{kind=link}