Statistische Grundlagen der Diagnostik, Testtheorie
| Сайт: | WueCampus |
| Курс: | vhb - Pädagogisch-Psychologische Diagnostik und Evaluation - Demo |
| Книга: | Statistische Grundlagen der Diagnostik, Testtheorie |
| Напечатано:: | Visiteur anonyme |
| Дата: | пятница, 3 июля 2026, 03:53 |
Описание
Wolfgang Schoppek, Bayreuth
Wolfgang Schoppek, Bayreuth - Statische Grundlagen der Diagnostik, Testtheorie
|
Ziele Für Diagnose elementare statistische Grundkonzepte (z.B. Mittelwert, Streuung, Verteilung, Korrelation) kennen und anwenden können, Kenntnisse in Testtheorie (Begriffsbestimmung, Testkonstruktion, testtheoretische Grundlagen). |
1. Einleitung
Alltagssprachlich assoziiert man mit dem Begriff Statistik vor allem die Sammlung und Darstellung großer Datenmengen und Sie stellen sich vielleicht die Frage, was das mit Diagnostik zu tun hat. Statistik ist aber auch der Name für die "Wissenschaft, die sich mit der Erhebung und Analyse von Daten befasst" (Zöfel, 2003, S. 11) – und Daten werden im diagnostischen Prozess immer erhoben und analysiert, selbst wenn es häufig nur um Einzelfälle geht. Bei der Interpretation der Daten ist zudem der Vergleich mit den Ergebnissen anderer Personen hilfreich. Auch dabei bedient man sich statistischer Konzepte und Methoden. Die Überprüfung der Gütekriterien eines Tests oder Fragebogens basiert ebenfalls größtenteils auf Verfahren aus der Statistik.
2. Verteilungen
Das in unserem Zusammenhang wichtigste Konzept der Statistik ist das der Verteilung. Misst man an einer Menge von Personen ein bestimmtes Merkmal, so ergibt sich eine Verteilung der gemessenen Werte. Da eine solche Verteilung empirisch erhoben wird, nennt man sie "empirische Verteilung". Es ist üblich, eine solche Verteilung grafisch in Form eines Säulendiagramms oder eines Histogramms darzustellen. Dazu teilt man den Bereich der gemessenen Werte in eine überschaubare Anzahl gleich großer Intervalle ein, die sich nicht überschneiden dürfen. Diese Intervalle werden auf der X-Achse abgetragen. Dann zählt man die Personen, deren Werte jeweils in einem Intervall liegen, und trägt die Anzahl als Säule auf der Y-Achse ab. An der Verteilungsgrafik kann man ablesen, über welchen Bereich sich die Messwerte erstrecken – man sagt auch, wie weit die Werte streuen – und welche Werte besonders häufig vorkommen.
Empirische Verteilungen haben häufig charakteristische Formen. So gibt es die meisten Fälle oft in der Mitte der Verteilung und die extremeren Werte verteilen sich in etwa symmetrisch um die Mitte herum. Eine solche Form nennt man auch "eingipfelig", wobei "Gipfel" das Intervall mit den meisten Fällen bezeichnet. Verteilungen, die dieser Form ähneln, können durch die statistischen Kennwerte Mittelwert und Standardabweichung gut beschrieben werden. Der Mittelwert einer Verteilung gehört zu den Maßen der zentralen Tendenz. Das gebräuchlichste unter diesen Maßen ist das arithmetische Mittel. Es wird gebildet, indem man alle Messwerte aufsummiert und durch die Anzahl der Fälle (meist Personen) teilt:
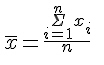
Gebräuchliche Abkürzungen für das arithmetische Mittel einer Verteilung sind (sprich "x quer"), M oder als sogenannter Populationsparameter µ (s.u.). Die Breite einer Verteilung wird durch sogenannte Dispersionsmaße beschrieben. Das zum arithmetischen Mittel gehörige Dispersionsmaß ist die Standardabweichung. Die Standardabweichung errechnet man, indem man die Summe der quadrierten Abweichungen jedes Messwertes vom Mittelwert durch die Anzahl der Fälle minus eins teilt und daraus die Wurzel zieht:
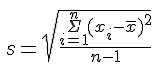
Die Standardabweichung ist aus einem weiteren wichtigen Maß, der Varianz, abgeleitet. Die Berechnung der Varianz entspricht der der Standardabweichung, nur dass die Wurzelziehung wegfällt; die Varianz ist also gleich der Standardabweichung zum Quadrat. Sie wird entsprechend meist mit s2 bezeichnet. Varianzen sind von den Zahlenwerten weniger anschaulich als Standardabweichungen, haben aber vorteilhafte mathematische Eigenschaften, die für Berechnungen genutzt werden.
Theoretische Überlegungen zu den stochastischen Prozessen (Zufallsprozessen), die empirischen Verteilungen zugrunde liegen, führen zu theoretischen Verteilungen. Die bekannteste davon ist die Normalverteilung. Theoretisch folgt die Verteilung eines Merkmals dann der Normalverteilung, wenn es von mehreren, unabhängig voneinander variierenden Einflussfaktoren abhängt. Man spricht dann auch davon, dass das Merkmal normalverteilt sei.
Die Normalverteilung ist durch die beiden Parameter Mittelwert und Standardabweichung vollständig festgelegt. Das bedeutet, dass Normalverteilungen mit unterschiedlichen Mittelwerten und Standardabweichungen recht unterschiedlich aussehen können. Sie können dies mit dem Applet "Normalverteilung" nachvollziehen. Bei der Darstellung von theoretischen Verteilungen wird die jeweilige Merkmalsausprägung auf der X-Achse abgetragen. Auf der Y-Achse wird die sogenannte Dichte dargestellt. Vereinfacht ausgedrückt entspricht die Dichte der erwarteten Häufigkeit von Fällen1.
Normalverteilung
Eine praktisch sehr bedeutsame Eigenschaft der Normalverteilung ist, dass man für alle Intervalle von Merkmalsausprägungen genau berechnen kann, welcher Anteil von Fällen innerhalb des Intervalls zu erwarten ist. Formal wird dazu das Integral der Dichtefunktion zwischen den Intervallgrenzen berechnet. Da das Integral anschaulich der Fläche unter der Dichtekurve entspricht, ist der erwartete Anteil von Fällen gleich dem Verhältnis der Fläche innerhalb der Intervallgrenzen zur Gesamtfläche unterhalb der Dichtekurve.
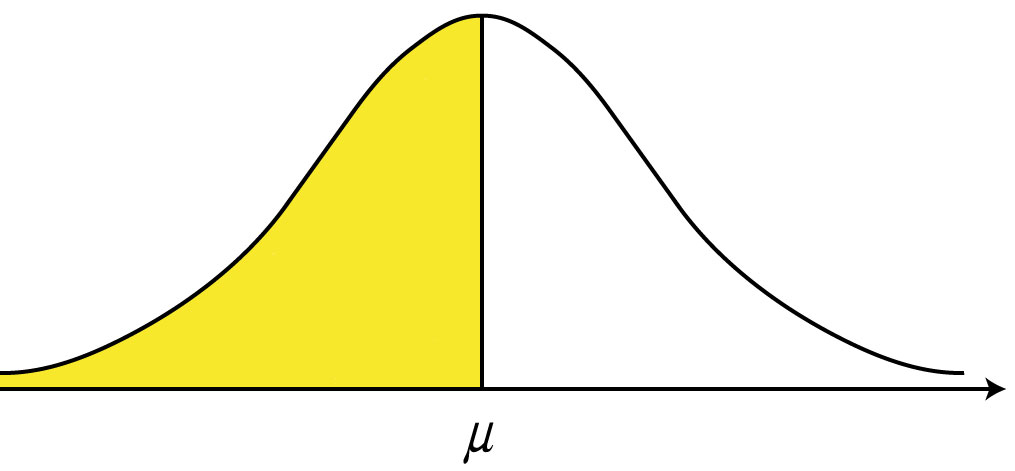
Abbildung 3.2: Integral unter einer NV-Kurve
Wir wollen dies am Beispiel der theoretischen Verteilung des Intelligenzquotienten nachvollziehen. Diese entspricht einer Normalverteilung mit einem Mittelwert von 100 und einer Standardabweichung von 15. Man kann nun angeben, welcher Anteil von Fällen mit einem IQ zwischen 100 und 115 zu erwarten ist: Es sind rund 34%. Fälle mit einem IQ größer als 130 sind dagegen nur 2,3% zu erwarten. Die erwarteten Häufigkeitsanteile der Abschnitte, die durch Vielfache der Standardabweichung gebildet werden, sind in Abbildung 3.4 angegeben.
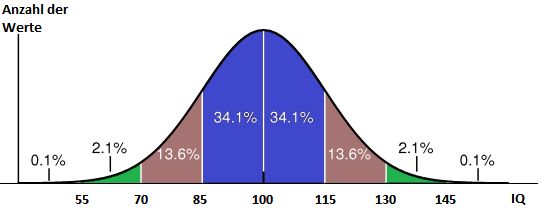
Abbildung 3.3: Anteile unter der NV-Kurve
In der Praxis muss man allerdings keine Integrale berechnen, sondern kann die entsprechenden Werte in Tabellen ablesen. Dazu wird die konkret vorliegende Verteilung per linearer Transformation in die Standardnormalverteilung umgerechnet, deren Mittelwert bei 0 und deren Standardabweichung bei 1 liegt. Da die Flächenverhältnisse unter der Dichtekurve von linearen Transformationen des Merkmals nicht verändert werden, ist dies ohne Informationsverlust möglich. Die Werte der Merkmalsausprägung werden also in sogenannte z-Werte umgerechnet und zwar nach folgender Formel:
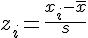
Man bezeichnet dies auch als z-Transformation. In Tabellen zur Standardnormalverteilung ist für jeden z-Wert der Flächenanteil unterhalb der Dichtekurve von minus unendlich bis zum jeweiligen z-Wert angegeben.
Etwas Ähnliches geschieht auch bei der Berechnung von Intelligenzquotienten. Da die Rohpunktwerte von Intelligenztests nicht so verteilt sind, dass sich im Mittel 100 Punkte ergeben, werden sie so transformiert, dass sich ein Mittelwert von 100 und eine Standardabweichung von 15 ergibt.
Neben der Normalverteilung gibt es eine Reihe weiterer theoretischer Verteilungen, wie etwa die Binomialverteilung, die die Verteilung von positiven Ausgängen binärer Ereignisse beschreibt, oder die Chi-Quadrat-Verteilung der Summe von n stochastisch unabhängigen, quadrierten normalverteilten Zufallsvariablen. Diese Verteilungen können aber im Rahmen des vorliegenden Kurses nicht besprochen werden. Stattdessen soll hier ein häufiges Missverständnis angesprochen werden: Es besteht in der Annahme, dass Schulleistungen, also auch die Ergebnisse von Klassenarbeiten, innerhalb einer Klasse normalverteilt sein sollten. Dies ist aus zwei Gründen falsch. Erstens sind bei Stichprobengrößen von etwa 30 Personen oder weniger deutliche Abweichungen der empirischen Verteilung von der theoretischen Verteilung wahrscheinlich. Das heißt, dass selbst wenn in der Population (also z.B. alle Neuntklässler in bayerischen Gymnasien) das Merkmal normalverteilt wäre, kann man für kleine, nicht zufällig gezogene Teilstichproben (Klassen) keineswegs erwarten, dass das Merkmal auch dort der Normalverteilung folgt. Dies liegt daran, dass nach dem Gesetz der großen Zahl Schätzungen statistischer Kennwerte – wozu man auch Verteilungen rechnen kann – erst bei größeren Stichproben genauer werden.
Zweitens ist es keineswegs immer sinnvoll, für Schulleistungen die Normalverteilung zu erwarten. Wenn ein Test beispielsweise zur Lernzielkontrolle durchgeführt wird, sollten die Ergebnisse hauptsächlich von einem Faktor – dem Unterricht – abhängen und nicht von einer Vielzahl zufällig variierender Einflussfaktoren. Wenn der Unterricht gut war, kann man durchaus Verteilungen erwarten, die deutlich in Richtung guter Leistungen verschoben sind.
Neben den gebräuchlichen Verteilungskennwerten arithmetisches Mittel und Standardabweichung gibt es weitere Kennwerte, die vor allem dann verwendet werden, wenn Daten vorliegen, die nicht auf Intervallniveau interpretiert werden dürfen. Auf die Datenniveaus werden wir in Kapitel 5 noch zu sprechen kommen. Hier seien vorerst nur die Maße kurz beschrieben: Der Median (Mdn) ist ein Maß der zentralen Tendenz, der gewissermaßen die Verteilung in zwei Hälften teilt. Ordnet man alle n Meßwerte einer Stichprobe der Größe nach, so entspricht der Wert an der Stelle n/2 dem Median. Das dazugehörige Dispersionsmaß ist der Quartilabstand; das ist die Differenz zwischen den Werten an den Stellen ¼ n und ¾ n. Bei Häufigkeitsverteilungen über Kategorien (also z.B. Berufe oder Länder) ist der Modalwert als Maß der zentralen Tendenz anzusehen. Er ist gleich dem Namen der Kategorie mit den meisten Fällen.
1 Streng genommen sind bei stetigen Zufallsvariablen Wahrscheinlichkeiten für das Auftreten einzelner Werte nicht ermittelbar, da es ja unendlich viele Möglichkeiten für einzelne Werte gibt. Es ist allerdings möglich, solche Wahrscheinlichkeiten für Intervalle von Werten anzugeben. Dies wird mit der Verteilungsfunktion ausgedrückt, die für jeden möglichen Wert die Wahrscheinlichkeit wiedergibt, dass der Wert mindestens so groß ist. Die Dichte entspricht demgemäß der ersten Ableitung der Verteilungsfunktion.
2.1 Zusammenfassung
.
3. Korrelationen
.
3.1 Zusammenfassung
.
4. Testtheorie
.
4.1 Die klassische Testtheorie
.
4.2 Probabilistische Testtheorie
.
4.3 Zusammenfassung
.
5. Literatur
.
6. Literaturverzeichnis
.
7. Übungsfragen
.